Ayuda:Generar imágenes con VQGAN+CLIP
![]()
![]()
![]()
![]()
![]()
![]()
VQGAN es una red generativa antagónica. Las Redes Neuronales Generativas Antagónicas (o Adversarias), también conocidas como GANs (Generative Adversarial Networks, en inglés), son una clase de algoritmos de inteligencia artificial que se utilizan en el aprendizaje no supervisado, implementadas por un sistema de dos redes neuronales que compiten mutuamente en una especie de juego de suma cero. Fueron presentadas por Ian Goodfellow et al. en 2014.
Esta técnica puede generar imágenes que parecen auténticas a observadores humanos. Por ejemplo, una imagen sintética de un gato que consiga engañar al discriminador (una de las partes funcionales del algoritmo), es probable que lleve a una persona cualquiera a aceptarlo como una fotografía real. La diferencia de VQGAN con redes GAN anteriores es que permite salidas en alta resolución.
CLIP (Contrastive Language Image Pretraining) es otra inteligencia artificial que permite transformar textos en imágenes. Es decir, en VQGAN+CLIP, CLIP introduce entradas de texto a VQGAN. Aquí te explicamos cómo usarlo.
VQGAN+CLIP en Google Colaboratory
Entrando en VQGAN+CLIP (z+quantize method con augmentations).ipynb realizada en Google Colaboratory por Katherine Crowson puedes arrancar un modelo VQGAN preformateado con unos valores y combinado con un modelo CLIP. Aquí te explicamos cómo hacerlo funcionar. Si prefieres una explicación en vídeo lee los enlaces externos de esta página. El canal Cogitare en YouTube te muestra cómo usarlo y el canal Dot CSV cómo funciona de manera técnica. En el canal de discord de DotCSV siguen proponiendo correcciones diariamente al notebook.
Pasos previos
- 2) Arriba a la derecha pulsa en
Conectarpara que se te asigne una máquina.



- 3) En la página hay círculos negros con una flecha con apariencia de "Play". Pulsa en estos botones para ejecutar cada una de las celdas.
- 4) Pulsa en la celda con el texto:
Licensed under the MIT License.
-

Nos saldrá esta advertencia.

- 5) Pulsa en la celda con el texto:
!nvidia-smi. Aquí aparecen los datos del PC remoto que va a ejecutar el modelo VQGAN+CLIP. La VRAM puede ser como ésta: 0MiB / 15109MiB. A más VRAM, más poder de renderizado. Con menos de 15109MiB podría no merecer la pena usar la máquina (tardando de media: 1 iteración 4 segundos, es decir, cuatro veces más que una de 15 GiB de RAM).

- 6) Pulsa en la celda con el texto:
Instalación de bibliotecas. Verás que en esa celda, aparecen barras de progreso. Eso son las instalaciones y descargas en curso. Espera a que acabe de descargar[1].
-

Este proceso ya no muestra la misma salida, pero es equivalente

- 7) Pulsa en la celda con el texto:
Selección de modelos a descargar. Puedes elegir descargar otros modelos pero el modelo por defectoimagenet_16384es bueno.imagenet_1024también es ligero.Time total,time spent,time leftindican cuánto tiempo falta de descarga. Espera a que acabe de descargar.
- 8) Pulsa en la celda con el texto:
Carga de bibliotecas y definiciones.
- 9) Pulsa en la celda con el texto:
Parámetros.
A la derecha de la celda parámetros hay una caja de texto que permite personalizarlos de manera más sencilla. Cada vez que modifiques los Parámetros vuelve a ejecutar la celda para que se actualice.
Parámetros
| Nombre del parámetro | Texto por defecto | Descripción |
|---|---|---|
textos |
A fantasy world |
Este parámetro es el texto que VQGAN+CLIP va a interpretar como concepto de la imagen. Si se escribe "fuego", dibujará fuego, y si se escribe "agua", representará agua. Más información en la sección "texto y contexto". |
ancho |
480 |
El ancho de cada imagen que VQGAN+CLIP generará dentro de esa página de Colaboratory. Se recomienda no modificarlo (más allá de 600) puesto que la máquina virtual tiene una memoria limitada. Es mejor utilizar después bigjpg. Puedes cambiar la proporción para que no sea cuadrada (Una ayuda aquí: Calculadora de proporciones). |
alto |
480 |
El alto de cada imagen que VQGAN+CLIP generará dentro de esa página de Colaboratory. Se recomienda no modificarlo (más allá de 600) puesto que la máquina virtual tiene una memoria limitada. Es mejor utilizar después bigjpg. También puedes cambiar la proporción. |
modelo |
imagenet_16384 |
Este parámetro decide qué modelo de VQGAN se va a ejecutar. Son cajas que permiten seleccionar uno o varios modelos. El que selecciones tiene que haber sido descargado previamente. El número indica la cantidad de modelos que contiene por lo que imagenet_16384 es mejor que imagenet_1024 (aunque más pesado).
|
intervalo_imagenes |
50 |
Esto indica al programa cada cuantas iteraciones imprime el resultado en la página. Si se escribe 50, imprimirá los resultados de las iteraciones 0, 50, 100, 150, 200, etc. |
imagen_inicial |
None |
Para usar una imagen inicial, sólo debes subir un archivo al entorno del Colab (en la sección a la izquierda), y luego modificar imagen_inicial: poniendo el nombre exacto del archivo. Ejemplo: sample.png. Ver Subir imágenes.
|
imagenes_objetivo |
None |
Una o más imágenes que la IA tomará como "meta", cumpliendo la misma función que ponerle un texto. Es decir, la IA intentará imitar la imagen o imágenes. Se separan con |.
|
seed |
-1 |
La semilla de esa imagen. -1 indica que la semilla será aleatoria cada vez. Al elegir -1 sólo verás en la interfaz de Colaboratory la semilla elegida en la celda "Hacer la ejecución", tal que así: Using seed: 7613718202034261325 (ejemplo). Si quieres averiguar las iteraciones y semillas de las imágenes que has descargado, están en los comentarios de la imagen. En Linux los visores normales incorporan los comentarios. En Windows los visores por defecto no pueden ver los metadatos, pero con Jeffrey's Image Metadata Viewer los puedes ver[r 1][r 2].
|
max_iteraciones |
-1 |
El número máximo de iteraciones antes de que el programa pare. Por defecto es -1, eso significa que el programa no va a parar a menos que no se cuelgue o se pare por otra razón. Se recomienda cambiarlo por un valor como 500, 600, 1000 o 3000. Un número más alto a veces no es necesario (la variabilidad desciende a mayor número de iteraciones). Recuerda que hacer estos cálculos es muy costoso energéticamente (y si dejas demasiado tiempo la sesión realizando cálculos tendrás una limitación en Google Colaboratory).
|
Texto y contexto
Idioma
La IA está entrenada mucho más en inglés por lo que muchas veces el contexto es mejor introduciendo la entrada en inglés. Esto se puede apreciar en las Imágenes al poner como entrada greek temples in space el resultado es mejor que con Templos griegos en el espacio.
Entradas separadas
Separar conceptos con barras verticales (también llamadas plecas o tuberías) ( | ) produce dos entradas distintas de texto, cada una con una "valor de pérdida"[r 3] independiente. Esto permite asignar efectos o adjetivos de manera independiente a diferentes elementos.
En la celda de ejecución se pueden ver separadas por comas y entrecomilladas.
- Texto:
Cosmic egg. - Name='cosmic egg'. (esto es lo que ejecuta el programa).
- Texto:
Bronze | space - Name='bronze' , 'space'.
Va a producir un resultado diferente de:
- Texto:
Bronze, space. - Name='bronze, space'.
Usar adjetivos
Se pueden utilizar adjetivos / estilos para variar la imagen sin variar los objetos que queremos que dibuje.
No hay una cantidad fija de estilos, hay tantos estilos como se nos puedan ocurrir.
Según artista
- Beksinski style / Dali style / Van Gogh style / Giger style / Monet style / Klimt / Katsuhiro Otomo style / Goya[r 4] / Miguel Angel (Sistine Chapel style) / Joaquin Sorolla style / Moebius style / in Raphael style (a veces contribuye a mejorar los trazados de los rostros).
- también se pueden mezclar.
En Wiki-art se consiguen mejores resultados incluso.
Según estilo de arte
- Calidades y distorsiones de cámara: 4k / chromatic aberration effect / cinematic effect / diorama / dof / depth of field / field of view / fisheye lens effect / photorealistic / hyperrealistic / raytracing / shaders / stop motion / tilt-shift photography / ultrarealistic / vignetting.
- cell shading / flat colors / full of color / electric colors.
- anime / comic / graphic novel / visual novel.
- Materiales: acrylic painting style / clay / coffee paint / collage / embroidery / glitch / graphite drawing / gouache / illuminated manuscript / ink drawing / medieval parchment / detailed oil painting / tempera / watercolor.
- isometric / lineart / lofi / lowpoly / photoshop / pixel art / vector art / voxel art.
- Períodos históricos: baroque / German Romanticism / impressionism / Luminism / pointillism / postimpressionism / Vienna Secession.
- Ver más aquí Art movement (en español: Movimientos artísticos.
- También se pueden utilizar tipo de pintura por regiones:
- chinese painting / indian art / tibetan paintings / nordic mythology style / soviet art style, etc.
Según películas o videojuegos
- in Ghost in the Shell style / in Star Wars style / in Ghibli style / in Metropolis film style / Death Stranding style…
- (cuanta más relación tenga el texto de entrada con la película o videojuego más se parecerá). Ver Las 1000 Mejores películas de la historia (2020).
Según programa de renderizado
Imita el resultado, no es que realmente esté usando esos motores gráficos[r 5]):
- rendered in Unreal Engine[r 6][r 7], el más usado.
- rendered in vray.
- rendered in povray.
- zbrush / cycles.
- rendered in rtx.
- rendered in octane.
- rendered in cinema4d.
- rendered in autodesk 3ds max.
- rendered in houdini.
- etc.
- Se pueden combinar.
- Pendiente: Comprobar: https://www.g2.com/products/octanerender/competitors/alternatives
Efectos específicos
- Añadir brdf / caustics / global-illumination / non-photorealistic / path tracing physically based rendering / raytracing / etc.
Efectos / luces
- diamond / fire / fog / glow / incandescent / iridiscent / lava / red-hot / shining / etc.
Otros modificadores
- Trending on (sitio web): por ejemplo "trending on artstation"[r 8]
- black hole / dismal / grim / liminal / minimalistic / surprising / vibrant.
Asignar pesos
También se pueden utilizar porcentajes y CLIP interpretará los decimales (0.1, 0.5, 0.8) como pesos de ese concepto en el dibujo (1 sería el total). También se pueden usar "porcentajes" (pero sin el símbolo de porcentaje). Se pueden usar pesos negativos para eliminar un color, por ejemplo.
- No interesa poner pesos inferiores a -1.
- Los pesos son relativos entre ellos (se recalcula el total y no tiene porqué coincidir con los números que se han puesto). Por eso se recomienda que sumen 100% —o 1— (más que nada para nosotros mismos saber los pesos reales).
Ejemplo de pesos con decimales:
- Texto:
rubber:0.5 | rainbow:0.5. Equivalente arubber:50 | rainbow:50.- Mal hecho: "0.5 rubber | 0.5 rainbow". (La asignación de pesos va después del concepto y después de
:). - Mal hecho: "awesome:100 adorable:300". (No está separado por
|) - Mal hecho: "rubber:50% | rainbow:50%". (Los
%no son signos admitidos).
- Mal hecho: "0.5 rubber | 0.5 rainbow". (La asignación de pesos va después del concepto y después de
Otros ejemplo de pesos (total 100):
- Texto:
sky:35 | fire:35 | torment:20 | dinosaurs:10
Ejemplo:
- Texto:
fantasy world | pink:0 - Resultado: No tiene rosa.
Nota: Eliminar una palabra mediante valores negativos puede cambiar por completo la imagen, con resultados inesperados. Si se es muy específico se pueden conseguir los resultados deseados, pero aún así la imagen cambiará mucho.
'Nota 2: Es mejor eliminar un concepto mediante valores a 0.
Por ejemplo para quitar el logo de Unreal:
- Texto:
… | logo of unreal:-1. Podría dar un resultado satisfactorio.
- Texto:
… | logo of unreal:0. Suele dar mejor resultado.
Mientras:
- Texto:
… | logo:-1. Dará un resultado totalmente diferente al ser demasiado poco específico.
Otros consejos
- Para imágenes astronómicas se consigue mejor resultado cuando se asignan pesos a los parámetros, así se definen mucho mejor los elementos (por ejemplo una galaxia).
- Los textos demasiado cortos suelen salir mal pero si son muy específicos no tanto.
- La IA deforma la cara de la gente cuando le pones el nombre de alguien en específico.
- Los humanos son el punto débil de la IA.
- Un truco que parece funcionar bien es usar como punto de partida una imagen de una cara humana producida por Artbreeder (una página web que también usa IAs con GAN).
- El punto de partida usando imágenes del propio VQGAN también es muy eficiente.
-

Usar imágenes anteriores del propio VQGAN+CLIP da muy buenos resultados, por Anarius.

Subir imágenes

Para usar una imagen inicial primero tienes que subirla.
- Ve a la parte izquierda y pulsa en "
Archivos" - Selecciona el icono que representa la subida "
Subir al almacenamiento de sesión". - Carga la imagen que quieras desde tu sistema de archivos (ponle un nombre reconocible).
- La imagen sólo permanecerá durante la sesión, luego se borrará.
- Después hay que modificar el apartado
imagen_inicialoimagenes_objetivoponiendo el nombre exacto del archivo. En el apartado deimagenes_objetivose pueden poner varias imágenes, usando|como separador.
Otras técnicas
Adaptar las imágenes a formas concretas
Para adaptar la imagen final a una forma concreta se pueden usar imágenes de inicio con máscaras de color haciendo esa forma. (Opcional, puede ser simplemente un cuadrado de color blanco, aunque será más preciso si se parte de la iteración 0) y se selecciona en el input cosas que se amolden a esa forma (por ejemplo, en una máscara redonda, un reloj, una pizza, una bola de cristal, etc.)
-

Se coge una imagen producida por la iteración 0.
-

Y en un programa de edición (GIMP o Photoshop) se elige una forma, dando fondo uniforme (del color que elijas). Esta imagen se usará como
imagen_inicial. -

Ejemplo: Con entrada
fisheye view of a corridor | graphite drawy usando comoimagen_inicialla máscara (por Abulafia).



Puedes añadir y descargar máscaras desde el Drive colaborativo de DotHub.
Guiar a la IA a un resultado
- Cuando se llega a una iteración en que se desvía de lo que se quiere. Se puede parar y usar ese último frame como nueva
imagen_inicial, modificando un poco la descripción. De ese modo hasta cierto punto se puede "guiar" a la IA hacia lo que se quiere. - Se itera un número N de pasos. Entonces se toma la imagen resultante, se le hace un pequeño zoom o desplazamiento y el resultado se usa como
imagen_inicial, para empezar de nuevo y hacer otros N pasos, etc.
Al final, tomando solo las imágenes que salen al final de cada una de esas iteraciones (una de cada N), Se monta el vídeo. Si se usa un número de pasos muy pequeño, salen cosas raras. Si usas muchos pasos tarda muchísimo. Un N=20 va más o menos bien.
Post-ejecución
Una vez hayas decidido los parámetros:
- Pulsa en la celda con el texto:
Hacer la ejecución… - Espera a que vayan apareciendo imágenes en ese celda.
- Cuando quieras guardar una imagen pulsa el botón derecho + Guardar imagen y guarda con el nombre que quieras.
Generar un vídeo
Se presiona su correspondiente "Play".
Si no se especifica el rango para el vídeo, generará un vídeo de todos los frames y puede tardar un rato. Para evitarlo puedes cambiar los parámetros en la celda como init_frame, last_frame y también los FPS.
Cuando termina el proceso a veces no carga y no es evidente dónde está el vídeo generado. Está en Archivos (barra lateral izquierda).

Actualización: Hay un nueva celda específica llamada Descargar vídeo, que realiza la descarga de manera automática.
Crear un zip con todas las imágenes
Esto aún no se ha activado en la versión en línea pero con el código que se muestra es totalmente funcional.
Si queremos descargar todos los pasos, hemos generado demasiadas imágenes y nos resulta muy tedioso guardarlas de una o en una o si, simplemente, hemos borrado o detenido la celda donde estaban las imágenes, aún se pueden descargar.
Los pasos intermedios que se generan (aunque no se muestren) se quedan en la carpeta /steps. Si queremos descargar todos los pasos, no es realizable el hacerlo a mano, por lo que los vamos a introducir en un único archivo y así descargarlos más fácilmente.
- Esto se aplica después de haber generado imágenes.
- Si la máquina se ha desconectado, no habrá archivos en
/stepspor lo que este procedimiento será inútil. Sí que puede que se conserven las imágenes que se muestran en la interfaz principal, por lo que se podrían guardar en grupo usando la extensión Download All images. Los enlaces a este complemento están en Más herramientas.
-

Celda de crear zip

| Nombre del parámetro | Texto por defecto | Descripción |
|---|---|---|
imagen_inicial |
0 |
Determina la primera imagen que se incluirá en el zip. |
imagen_inicial |
-1 |
Determina la última imagen que se incluirá en el zip. El -1 es el valor para la última.
|
paso |
50 |
Determina el intervalo entre una imagen y la siguiente. Por defecto es 50 igual que en el menú superior. Si se pone el intervalo a 1 guarda todos los pasos intermedios. El zip resultante pesará bastante, dependiendo de la cantidad de imágenes. Además, también influye en el tiempo que tarde en descargar. Si es demasiado grande puede tardar mucho y/o desconectarse la máquina en medio de la descarga. Normalmente al reconectar no se han borrado los archivos (pero puede darse el caso).
|
nombre_del_archivo |
archivos.zip |
Es el nombre del archivo que se descargará. Las imágenes dentro de la carpeta también tendrán este nombre y una numeración. Se recomienda poner nombres distintivos. |
Una vez generado el archivador zip generado está en la barra lateral izquierda, en debería descargarse automáticamente.
Archivos
Esta sección trata sobre un elemento que aún no está en línea. Si aún así quieres probarlo, este es el código. Requiere abrir una nueva entrada para comandos:
Abrir nuevas entradas para comandos
Para introducir una nueva entrada nos vamos con el ratón justo en el borde de una celda y al pasar por encima aparecerán dos pestañas: + Código y + Texto. Pulsamos + Código. Otra opción es usar Control+M B[2].
-

Al añadir una nueva celda podemos ejecutar comandos personalizados

Y pegar esto:
Código para generar zip
# @title Crear un zip con todas las imágenes (o algunas)
imagen_inicial = 0 #@param {type:"integer"}
imagen_final = -1 #@param {type:"integer"}
paso = 50 #@param {type:"integer"}
nombre_del_archivo = "archivos.zip" #@param {type:"string"}
import zipfile
if imagen_final == -1:
imagen_final = i
zipf = zipfile.ZipFile(nombre_del_archivo, 'w', zipfile.ZIP_DEFLATED)
for i in tqdm(range(imagen_inicial, imagen_final+1, paso)):
fname = f"{i:04}.png"
zipf.write(f"steps/{fname}", f"{nombre_del_archivo.split('.')[0]}-{fname}")
zipf.close()
print(nombre_del_archivo, "creado. Descargando… Se abrirá el diálogo de descargas cuando finalice la descarga.")
from google.colab import files
files.download(nombre_del_archivo)
Si se hace más de un zip hay que dar permiso en Chrome para descargar varios archivos.
Importante en el caso de descargar todas las imágenes: Si tenemos muchos archivos y poco espacio puede fallar (especialmente si se combina con utilizar modelos muy pesados, como COCO-stuff o después de haber generado un vídeo). Si ese fuera el caso y no fuéramos a usar de nuevo la máquina con ese modelo podríamos borrar el modelo en concreto para hacer espacio o el vídeo, una vez descargado.
Controlar el notebook desde el teclado / ejecución automatizada
Controlar el notebook desde el teclado
Para controlar el notebook desde el teclado necesitamos entender el concepto de "foco". El foco es el lugar donde se encuentra la "selección" en cada momento. Si una ventana, elemento, celda, cuadro de texto, etc. tiene foco significa que puede recibir directamente órdenes desde el teclado.
Las combinaciones de teclas que usaremos para navegar por el notebook son pocas: Control+Enter para ejecutar una celda, ↓ para cambiar de celda y ↹ (la tecla tabulador, encima del bloqueo de mayúsculas), para movernos por menús o dentro de una celda.
Pasos:
1) Centrar el foco en la primera celda (bajando con ↓ una vez).
2) Ejecutar la segunda celda (Licensed under the MIT License). Saldrá un menú donde tenemos que aceptar (↹ y Enter), pasaremos a la siguiente celda y las ejecutaremos de manera sucesiva[1] hasta llegar a Parámetros que es una celda de texto, por lo que no se ejecuta. En Parámetros iremos eligiendo los campos necesarios moviéndonos con el tabulador (↹).
3) movernos con el tabulador hacia atrás (Shift+↹) o hacia delante hasta llegar a la cabecera de una celda y seguimos moviéndonos para abajo ↓ para ejecutar Hacer la ejecución. En el caso de querer guardar como zip (ver Crear un zip con todas las imágenes) o Guardar como vídeo, nos moveremos a sus respectivas celdas. Actualmente tendríamos que introducir manualmente la celda (ver Abrir nuevas entradas para comandos).
Ejecución automatizada
Ir a la sección de Parámetros (o Selección de modelos a descargar en el caso de querer usar uno diferente del de por defecto) y una vez rellenados los parámetros deseados ir al menú Entorno de ejecución → Ejecutar anteriores o presiona Control+F8.
Montar Google Drive

|
ADVERTENCIA DE FALTA DE CONTENIDO: Esta sección es un borrador, que se encuentra (evidentemente) incompleto. Sé paciente |
|---|
En el menú lateral pinchamos en Activar Drive. Es botón añadirá automáticamente un bloque de código. Si no carga/funciona el menú lateral prueba a añadirlo en una nueva celda, con este código:
from google.colab import drive
drive.mount('/content/drive')
Preguntas frecuentes de VQGAN+CLIP
¿Cómo parar la ejecución del programa?
Por defecto max_iteraciones es -1, eso significa que no va a parar de hacer iteraciones. Si quieres parar el proceso puedes pulsar el botón circular de fondo gris con una X blanca con tooltip "borrar resultado". Antes de borrar asegúrate de guardar lo que quieras.
El atajo para detener una celda es Control+M I[2].
-

También se puede parar en la X que aparece en la barra de estado inferior.
A veces una celda se queda "colgada". Entonces se puede borrar en el botón de eliminar (símbolo de la papelera). Para restaurarla usa Control+M Z[2].
¿Cómo sé si una celda se ha ejecutado?
Si te posicionas en el botón de "Play" de una celda se ve si se ha ejecutado y el resultado de la ejecución.
-

Estado de ejecución.

Subo una imagen pero sale distorsionada desde el inicio
Eso es porque 480x480 es una imagen cuadrada. Si subes una imagen con una proporción diferente a 1:1, se distorsionará desde el principio. Calcula la proporción de la imagen que vas a subir y utiliza la misma proporción en los campos ancho y alto si quieres que no se produzca esta distorsión. Puedes usar esta Calculadora de proporciones.
A veces pongo un valor, pero no lo toma
Eso es porque no has vuelto a ejecutar la celda. Cualquier cambio en los campos de Parámetros necesita que la celda vuelva a ejecutarse.
He puesto un valor límite pero quiero continuar con más iteraciones
No es necesario volver a iterar desde el principio para continuar con un resultado (aunque tendrías que conocer el seed o haberlo averiguado mediante la herramienta Steganography Online), puedes usar como imagen_inicial la última imagen iterada. Ver Guiar a la IA a un resultado.
No sé si tengo que volver a ejecutar todo desde el principio (la máquina se ha desconectado)
Aunque a veces conserva los paquetes y definiciones en memoria aunque haya pasado mucho tiempo, otras veces no y hay que volver a empezar desde el principio. Se puede comprobar fácilmente mirando si la celda se ha ejecutado en la sesión actual. Ver ¿Cómo sé si una celda se ha ejecutado? o intentando ejecutar la celda Parámetros y mirando el error.
¿Qué modelo me conviene?
|
|
ADVERTENCIA DE FALTA DE CONTENIDO: Esta sección es un borrador, que se encuentra (evidentemente) incompleto. Sé paciente |
|---|
Los modelos no tienen ventajas evidentes entre ellos. Han sido entrenados con conjuntos de imágenes diferentes por lo que producirán resultados diferentes, no necesariamente mejores o peores.
- ImageNet: El proyecto ImageNet es una gran base de datos visual diseñada para su uso en la investigación de software de reconocimiento visual de objetos. El proyecto ha anotado a mano más de 14 millones de imágenes para indicar qué objetos se representan y en al menos un millón de las imágenes, también se proporcionan cuadros delimitadores. Contiene más de 20.000 categorías con una categoría típica, como "globo" o "fresa", que consta de varios cientos de imágenes (vía wikipedia en inglés).
Frente a lo que pudiera suponerse, que uno tenga un codebook más grande no significa exactamente que sea más potente, simplemente le permite capturar más características de las imágenes. Eso puede ser bueno o no, dependiendo de qué tipo de resultados se quieran conseguir. El de 1024 es un poco "más libre" por así decir a la hora de generar imágenes. Tiende a crear cosas más abstractas, más caóticas, y más artísticas. Su "visión del mundo" tiene menos categorías, lo que le obliga a abstraer más.
16384 es mucho mejor para fondos suaves o minimalistas.
Se puede ver una comparativa entre algunas imágenes de 1024 vs 16384 en este colab: Reconstruction usage.
COCO-Stuff(Proyecto - 7.86 GiB - FID[3]: 20.4): COCO-Stuff es una modificación con "augmentos" del un conjunto de datos (=dataset) COCO de Microsoft, con imágenes cotidianas (calles, personas, animales, interiores…).
faceshq(3.70 GiB). Especializado en caras.
- Wikiart: Las imágenes del conjunto de datos de WikiArt se obtuvieron de WikiArt.org. Licencia: Solo para fines de investigación no comerciales. Es decir, es un conjunto entrenado con cuadros de arte por lo que los resultados generalmente serán pinturas. Un resultado similar se podría conseguir en los conjuntos de datos de
imagenetusando estilos de pintores famosos.wikiart_1024(913.75 MiB): Versión de wikiart con un codebook de 1024 elementos.wikiart_16384(958.75 MiB): Versión de wikiart con un codebook de 16384 elementos.
s-flckr(3.97 GiB ): Conjunto desde Flickr.ade20k(4.61 GiB - FID[3]: 35.5) (Nota: no está por defecto, ver ¿Cómo puedo añadir nuevos modelos?): Conjunto de datos con segmentación semántica del MIT. Contiene más de 20K imágenes centradas en escenas con anotaciones exhaustivas con objetos a nivel de píxel y etiquetas de partes de objetos. Hay un total de 150 categorías semánticas, que incluyen cosas como cielo, carreteras, césped y objetos discretos como personas, coches, camas, etc.
¿Cómo puedo añadir nuevos modelos?
|
|
ADVERTENCIA DE FALTA DE CONTENIDO: Esta sección es un borrador, que se encuentra (evidentemente) incompleto. Se completará próximamente |
|---|
Por completar.
Notebook modificado con ade20k, ffhq y celebahq.
He dejado abierto toda la noche VQGAN y ahora no conecta a una máquina con GPU
Aunque "no esté haciendo nada" que la conexión exista ya gasta tiempo asignado con lo que si dejas la máquina parada durante un tiempo largo la próxima vez no te asignarán una máquina con GPU.
Solución:
- Evita dejar la máquina conectada más tiempo del necesario.
- Espera el tiempo suficiente (1 día o así) a que pase la limitación.
- Utiliza otra cuenta de gmail diferente.
- Si tienes una paciencia infinita, puedes usar la máquina sólo con CPU. Tarda del orden de 30 veces más.
¿Cuáles son los límites de uso de Colab?
Colab puede proporcionar recursos gratuitos en parte al tener límites de uso dinámicos que a veces fluctúan y al no proporcionar recursos garantizados o ilimitados. Esto significa que los límites de uso general, así como los períodos de inactividad, la vida útil máxima de la máquina virtual, los tipos de GPU disponibles y otros factores varían con el tiempo. Colab no publica estos límites, en parte porque pueden (y a veces lo hacen) variar rápidamente.
Las GPU y las TPU a veces se priorizan para los usuarios que usan Colab de forma interactiva en lugar de para los cálculos de larga duración, o para los usuarios que recientemente han usado menos recursos en Colab. Como resultado, los usuarios que usan Colab para cálculos de larga duración, o los usuarios que recientemente han usado más recursos en Colab, tienen más probabilidades de encontrarse con límites de uso y tener su acceso a GPU y TPU restringido temporalmente. Los usuarios con grandes necesidades computacionales pueden estar interesados en utilizar la interfaz de usuario de Colab con un tiempo de ejecución local que se ejecuta en su propio hardware. Los usuarios interesados en tener límites de uso más altos y estables pueden estar interesados en Colab Pro[r 10].
¿Cómo puedo subir una imagen desde internet directamente?
|
|
ADVERTENCIA DE FALTA DE CONTENIDO: Esta sección es un borrador, que se encuentra (evidentemente) incompleto. En investigación |
|---|
Si tienes poca conexión a veces la funcionalidad de subir una imagen falla o no carga. Se puede utilizar este código para descargar la imagen desde una URL de internet.
!wget https://url.hacia.tu/imagen.jpg
Permite descargar una URL desde internet hacia el notebook. Ver Abrir nuevas entradas para comandos.
Si utilizas la opción -O puedes elegir el nombre deseado (fíjate en el orden):
!wget -O destino.jpg https://url.hacia.tu/imagen.jpg
Se pueden descargar varias imágenes separando cada comando wget por un enter.
¿Cómo puedo ejecutar VQGAN+CLIP en local?
|
|
ADVERTENCIA DE FALTA DE CONTENIDO: Esta sección es un borrador, que se encuentra (evidentemente) incompleto. Se completará próximamente |
|---|
El problema es que ejecutarlo en local te pedirá una gráfica muy potente. Aproximadamente necesitas a partir de 15GB de GPU aproximadamente para que te vaya decente. Con mínimo 10GB, correrá, pero extremadamente lento.
Hay personas que han conseguido hacerlo usable con tarjetas gráficas (1060) de 6GB. Una posible solución de optimización sería modificar el parámetro cutn (por ejemplo a 32). Si se baja demasiado el parámetro (que tiene que ver con la calidad), no da resultados buenos, pero si es muy alto, consume mucha memoria.
En Ejecución local hay versiones de Docker y en github.
¿Cómo puedo desactivar las augmentaciones?
Las augmentaciones son variaciones aleatorias en cada paso que mejoran la calidad final de la imagen. Es decir, si se desactivan se pierde calidad, pero la ejecución será más rápida (aunque no mucho 1.01 segundos cada iteración vs 1.31 segundos cada iteración (en una Tesla T4). También puede variar sustancialmente el contenido.
En la celda Carga de bibliotecas pulsamos dos veces y aparecerá el código editable. Buscamos (Control+F) este código class MakeCutouts(nn.Module): y quitamos de self.augs = nn.Sequential() todo lo que va entre paréntesis, Quedando así:
class MakeCutouts(nn.Module):
def __init__(self, cut_size, cutn, cut_pow=1.):
super().__init__()
self.cut_size = cut_size
self.cutn = cutn
self.cut_pow = cut_pow
self.augs = nn.Sequential()
self.noise_fac = 0.1
-

Estado normal
-

Estado final sin augmentaciones


Resultados:
-

medusa hydra chimera hybrid monster flying in saturn | vray unreal engine style, i=550. Con augmentaciones (por defecto). -

medusa hydra chimera hybrid monster flying in saturn | vray unreal engine style, i=550. Sin augmentaciones.


No se recomienda.
Solución de errores de VQGAN+CLIP

Aquí se citan algunos de los errores que te puedes encontrar y cómo solucionarlos.
NameError: name 'textos' is not defined
NameError Traceback (most recent call last)
<ipython-input-6-b687f6112952> in <module>()
2 device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
3 print('Using device:', device)
----> 4 if textos:
5 print('Using texts:', textos)
6 if imagenes_objetivo:
NameError: name 'textos' is not defined
Solución: Has pulsado en Hacer la ejecución… antes de cargar los parámetros. Detén la celda Hacer la ejecución.. y pulsa en ejecutar la celda de Parámetros. Después pulsa de nuevo en "Hacer la ejecución…" de nuevo.
NameError: name 'argparse' is not defined
NameError Traceback (most recent call last)
<ipython-input-8-9ad04e66b81c> in <module>()
29
30
---> 31 args = argparse.Namespace(
32 prompts=textos,
33 image_prompts=imagenes_objetivo,
NameError: name 'argparse' is not defined
Solución: Esto significa que no has ejecutado la celda "Carga de bibliotecas y definiciones". (Por supuesto también puede ser que se haya caducado la máquina virtual).
ModuleNotFoundError: No module named 'transformers'
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-12-a7b339e6dfb6> in <module>()
13 print('Using seed:', seed)
14
---> 15 model = load_vqgan_model(args.vqgan_config, args.vqgan_checkpoint).to(device)
16 perceptor = clip.load(args.clip_model, jit=False)[0].eval().requires_grad_(False).to(device)
17
11 frames
/content/taming-transformers/taming/modules/transformer/mingpt.py in <module>()
15 import torch.nn as nn
16 from torch.nn import functional as F
---> 17 from transformers import top_k_top_p_filtering
18
19 logger = logging.getLogger(__name__)
ModuleNotFoundError: No module named 'transformers'
Solución: Sucede con coco, faceshq y sflickr. Hay que abrir una celda antes de Carga de bibliotecas y definiciones y poner:
!pip install transformers
Y ejecutar esa celda.
ModuleNotFoundError: No module named 'taming'
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-10-c0ac0bf55e51> in <module>()
11 from omegaconf import OmegaConf
12 from PIL import Image
---> 13 from taming.models import cond_transformer, vqgan
14 import torch
15 from torch import nn, optim
ModuleNotFoundError: No module named 'taming'
Solución: Posiblemente reiniciar el entorno o ver la solución de ModuleNotFoundError: No module named 'transformers'.
ModuleNotFoundError: No module named 'taming.modules.misc'
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-11-b687f6112952> in <module>()
13 print('Using seed:', seed)
14
---> 15 model = load_vqgan_model(args.vqgan_config, args.vqgan_checkpoint).to(device)
16 perceptor = clip.load(args.clip_model, jit=False)[0].eval().requires_grad_(False).to(device)
17
12 frames
/usr/lib/python3.7/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
ModuleNotFoundError: No module named 'taming.modules.misc'
Solución: Uno de los paquetes necesarios para ejecutar el programa falla. Ejecuta de nuevo la celda de instalación de paquetes e inténtalo de nuevo.
- Si elegías el modelo "
faceshq" te podía salir este error. Este error ya ha sido corregido (2021-06-11).
FileNotFoundError: [Errno 2] No such file or directory
FileNotFoundError Traceback (most recent call last)
<ipython-input-10-f0ccea6d731d> in <module>()
13 print('Using seed:', seed)
14
---> 15 model = load_vqgan_model(args.vqgan_config, args.vqgan_checkpoint).to(device)
16 perceptor = clip.load(args.clip_model, jit=False)[0].eval().requires_grad_(False).to(device)
17
1 frames
/usr/local/lib/python3.7/dist-packages/omegaconf/omegaconf.py in load(file_)
181
182 if isinstance(file_, (str, pathlib.Path)):
--> 183 with io.open(os.path.abspath(file_), "r", encoding="utf-8") as f:
184 obj = yaml.load(f, Loader=get_yaml_loader())
185 elif getattr(file_, "read", None):
FileNotFoundError: [Errno 2] No such file or directory: '/content/wikiart_16384.yaml' (alternativa: Orange.png)
Solución: Esto puede significar dos cosas:
- Has elegido un modelo que no has descargado antes. Comprueba que el modelo elegido se haya descargado. También puede ser que la máquina haya caducado (es decir, se ha borrado todo). En este último caso tendrías que ejecutar todo desde el principio.
- Has puesto un nombre en
imagen_inicialque no se corresponde con la imagen que has subido. Este programa detecta como diferentes las mayúsculas de las minúsculas por lo queOrange.pnges diferente queorange.png. Pon el nombre correcto enimagen_inicial.
- Si por accidente has subido una imagen con un nombre muy complicado puedes cambiarle el nombre desde la propia interfaz.
-

En el panel de
Archivosa la derecha de cada archivo hay unas columnas de puntos donde al pulsar se puede cambiar el nombre.

RuntimeError: CUDA out of memory
RuntimeError Traceback (most recent call last)
<ipython-input-13-f0ccea6d731d> in <module>()
131 with tqdm() as pbar:
132 while True:
--> 133 train(i)
134 if i == max_iteraciones:
135 break
8 frames
/usr/local/lib/python3.7/dist-packages/taming/modules/diffusionmodules/model.py in nonlinearity(x)
29 def nonlinearity(x):
30 # swish
---> 31 return x*torch.sigmoid(x)
32
33
RuntimeError: CUDA out of memory. Tried to allocate […] (GPU 0; […] total capacity; […] already allocated; […] free; […] reserved in total by PyTorch)
Solución: Esto puede significar varias cosas:
- Has elegido unas dimensiones de imagen demasiado grandes. El tamaño 480x480px es suficiente (aunque en teoría podría soportar hasta 420000 píxeles en total, es decir ~648x648). Para ampliar las dimensiones de la imagen utiliza las herramientas enlazadas en Ampliar imágenes.
- Te has quedado sin memoria por usarlo mucho tiempo. Tendrás que iniciar una nueva sesión.
- Google te ha asignado una GPU de baja memoria (<15109MiB). Tendrás que iniciar una nueva sesión.
RuntimeError […] is too long for context length X
RuntimeError Traceback (most recent call last)
<ipython-input-10-f0ccea6d731d> in <module>()
46 for prompt in args.prompts:
47 txt, weight, stop = parse_prompt(prompt)
---> 48 embed = perceptor.encode_text(clip.tokenize(txt).to(device)).float()
49 pMs.append(Prompt(embed, weight, stop).to(device))
50
/content/CLIP/clip/clip.py in tokenize(texts, context_length)
188 for i, tokens in enumerate(all_tokens):
189 if len(tokens) > context_length:
--> 190 raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
191 result[i, :len(tokens)] = torch.tensor(tokens)
192
RuntimeError: Input […] is too long for context length 77
Solución. El texto introducido es muy largo. Introduce un texto más corto. Tiene que ser menor de 350 caracteres[r 11]. Ver Contar caracteres.
TypeError: randint() received an invalid combination of arguments
TypeError Traceback (most recent call last)
<ipython-input-8-b8abd6a7071a> in <module>()
43 z, *_ = model.encode(TF.to_tensor(pil_image).to(device).unsqueeze(0) * 2 - 1)
44 else:
---> 45 one_hot = F.one_hot(torch.randint(n_toks, [toksY * toksX], device=device), n_toks).float()
46 if is_gumbel:
47 z = one_hot @ model.quantize.embed.weight
TypeError: randint() received an invalid combination of arguments - got (int, list, device=torch.device), but expected one of:
* (int high, tuple of ints size, *, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (int low, int high, tuple of ints size, *, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
Solución: No se conoce aún qué provoca este error, puesto que solo aparece con determinadas configuraciones (no por defecto). La solución temporalmente debería ser cambiar los parámetros hasta que funcione.
ValueError: could not convert string to float
ValueError Traceback (most recent call last)
<ipython-input-8-f0ccea6d731d> in <module>()
45
46 for prompt in args.prompts:
---> 47 txt, weight, stop = parse_prompt(prompt)
48 embed = perceptor.encode_text(clip.tokenize(txt).to(device)).float()
49 pMs.append(Prompt(embed, weight, stop).to(device))
<ipython-input-5-32991545ebb9> in parse_prompt(prompt)
129 vals = prompt.rsplit(':', 2)
130 vals = vals + ['', '1', '-inf'][len(vals):]
--> 131 return vals[0], float(vals[1]), float(vals[2])
132
133
ValueError: could not convert string to float: ' los leones la levantan y[…]'
Solución: El texto contenía dos puntos :, carácter ilegal si no es en una sentencia determinada (red:-1, por ejemplo).
WARNING:root:kernel restarted

Aunque intentes reconectar, o volver a ejecutar las celdas, la máquina parece que se ha quedado muerta. Por (por ejemplo) el error WARNING:root:kernel […] restarted.
Solución: Forzar la finalización de la sesión, yendo a la pestaña superior al lado de Conectar → Gestionar sesiones → Finalizar.

Ejemplos
Imágenes
- Sin entrada de imagen:
-

Texto:
greek temples in space. 300 iteraciones. -

Texto:
Templos griegos en el espacio. 300 iteraciones. -

Texto:
Chinese, bronze, funeral. 300 iteraciones. -

Texto:
Diplodocus, surf. 300 iteraciones.




- Con entrada de imagen:
-

Entrada de imagen: (Dussiano), por Khang Le.
-

Salida de imagen con 50 iteraciones y texto "
Modern spaceship insect alien". -

Salida de imagen con 1500 iteraciones y texto "
Modern spaceship insect alien".



-

Entrada de imagen: Eli, la mascota de menéame, por Meneame.net
-

Texto:
orange elephant. 400 iteraciones. -

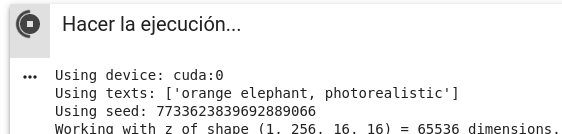
Texto:
orange elephant, photorealistic. 850 iteraciones. -

Texto:
orange elephant | photorealistic. (misma semilla que la anterior). 300 iteraciones.




{kind=link}
Ejemplos de vídeo
Véase también
Referencias
Las Referencias aluden a las relaciones de un artículo con la "vida real".
- ↑ Nota: Una alternativa a los metadatos XMP son los datos introducidos mediante esteganografía. Estos metadatos se pueden visualizar mediante la librería stegano de python (Steganography Online).
- ↑ Nota 2: Aunque la semilla sea idéntica los resultados aún así variarán un poco debido a las "augmentaciones". Las aumentaciones son variaciones pseudoaleatorias introducidas en cada iteración. Se pueden desactivar, lo que haría que fuera un poco más rápido, pero a costa de perder calidad. Ver ¿Cómo puedo desactivar las augmentaciones?
- ↑ Hinge loss o pérdida de articulación, es un tipo de función de pérdida específico para las inteligencias artificiales. Ver hinge loss.
- Traducción semiautomática: En el aprendizaje automático, la "pérdida de articulación" es una función de pérdida que se utiliza para entrenar clasificadores. La pérdida de articulación se utiliza para la clasificación de "margen máximo", sobre todo para las máquinas de vectores de soporte (SVM).
- ↑ En Goya y otros artistas se ha apreciado que las primeras iteraciones son mejores.
- ↑ Es decir, la IA se ha entrenado con muchas imágenes, algunas de las cuales estaban etiquetadas con "rendered en X" por lo que imita esos resultados
- ↑ Vía Aran Komatsuzaki.
- ↑ En el apartado Asignar pesos se muestra una forma de intentar quitar el logo de Unreal Engine que a veces aparece flotando por la imagen.
- ↑ Aunque la palabra "trending" evoque algo actual, el conjunto de datos (=dataset) no se actualiza cada día. Es decir, ese "trending" será tomando los datos del momento en el que se hizo el conjunto de datos (=dataset).
- ↑ Es decir, el número de elementos que utiliza el modelo para definir una única imagen Ver ¡Esta IA crea ARTE con tus TEXTOS! (y tú puedes usarla 👀) [Minuto 7:30].
- ↑ Referencia.
- ↑ Como tal no hay límite de caracteres, sino de tokens (que son un grupo de caracteres), pero los tokens varían dependiendo de lo que escribas. Según tengo entendido, son máximo 75 tokens aproximadamente 350 caracteres.
- ↑ 1,0 1,1 1,2 Antes de tener dominio del programa se recomienda esperar a que termine cada celda de ejecutar (para no saltarse pasos). Pero en realidad no es necesario. Se puede programar de principio a fin (incluso vídeo) rellenando los parámetros correctos. Obviamente, si la máquina caduca, el vídeo no podrá descargarse, por lo que hay que echarle un ojo de vez en cuando.
- ↑ 2,0 2,1 2,2 Estos atajos se activan pulsando primero las dos teclas unidas por el + y después la letra adicional.
- ↑ 3,0 3,1 3,2 3,3 La puntuación de distancia de inicio de Frechet, o FID para abreviar, es una métrica que calcula la distancia entre los vectores de características calculados para imágenes reales y generadas. Vía: How to Implement the Frechet Inception Distance (FID) for Evaluating GANs.
Enlaces externos
Los enlaces externos no están avalados por esta wiki. No nos hacemos responsables de la caída o redirección de los enlaces.
Información
- * http://bit.ly/VQGANwiki. Enlace corto del este artículo.
Vídeos
- Taming transformers for high-resolution image synthesis.
- Cogitare: De TEXTO a OBRA DE ARTE | Te enseño a usar esta IA revolucionaria, de Cogitare.
- De dot_CSV:
- ¡Esta IA crea ARTE con tus TEXTOS! (y tú puedes usarla 👀), de dot_CSV.
- ¡Descubre Cómo la IA será MÁS POTENTE! - 👁🗨VISIÓN + LENGUAJE NATURAL💬, de dot_CSV.
- ¿Es esta IA el FIN de los DISEÑADORES GRÁFICOS? ¿Puede la IA ser CREATIVA?. DALL-E es una IA diferente a VQGAN.
- These Neural Networks Have Superpowers.
Información técnica
- Taming transformers for high-resolution image synthesis.
- Proyecto CLIP en github.
- Redes Neuronales Generativas Adversarias.
Otras guías
- Cómo crear imágenes artísticas fácilmente con una IA: VQGAN.
- Brutal aplicación de texto a imagen (VQGAN+CLIP).
Ejecución local
- Docker para ejecutarlo localmente.
- Imagen en docker por xekex#5678.
- Gist en github con instalación en local.
Otras herramientas
Recursos para imágenes de inicio
- Phylopic. Siluetas de animales. Dominio público.
- Drive colaborativo de DotHub.
- Garabatos a caras.
- Artrbreeder.
Ampliación de imágenes
![]() Artículo principal: Ayuda:Ampliadores de imágenes con IA.
Artículo principal: Ayuda:Ampliadores de imágenes con IA.
- Waifu2x. Ampliador de imágenes. Gratuito.
- Instalable. Ver waifu2x, waifu2x extension-gui, waifu2x-caffe, waifu2x-converter-cpp.
- DeepAI Waifu2x. Gratuito.
- bigjpg. Ampliador de imágenes. Sólo 20 gratis.
- Upscaler. Ampliador de imágenes. Sólo 3 gratis.
- Notebook ESRGAN. (Comparativa con waifu2x).
Visores de metadatos
- Jeffrey's Image Metadata Viewer. Visor de datos EXIF.
- Steganography Online. Visor de datos introducidos mediante esteganografía. (Usar la pestaña "Decode").
Más herramientas
- Imgops.com. Múltiples operaciones de imágenes.
- Calculadora de proporciones.
- Contador de caracteres.
- Dowload all images para Chrome.
- Download All Images para Firefox.
Generadores de entradas de texto
- EleutherAI. Generador IA potente.
- GPT-J6B Demo.
- GPT-Neo.
- Noemata titlegen. No IA. Genera nombres "surrealistas". Pueden ser una entrada de texto interesante si no se te ocurre otra cosa.
Notebooks
- Lucid Sonic Dreams. A partir de una música hace una animación.
- BigGAN + CLIP.
- codebook sampling method (original).
- TheBigSleep.
- http://bit.ly/VQGAN. Enlace corto del notebook .
- DeepDaze (notebook original).
- DeepDaze (notebook simplificado).
Redes sociales
- Discord de DotHub, en español.
- Discord de El Bestiario del Hypogripho Dorado. Por si tienes dudas sobre el tutorial.
- Reddit, en inglés.
Agradecimientos
Agradecimiento especial a Eleiber#8347 por contestar mis dudas y proporcionar correcciones. También a Abulafia#3734 por explicarme técnicas y a elchampi#0893 por compartir sus dudas. Y a muchos usuari@s del discord de DotHub que han compartido sus técnicas o dudas. También a los usuarios de Reddit que me han ayudado.
⚜️
| |
Artículo redactado por Jakeukalane Para proponer cualquier cambio o adición, consulte a los redactores. |
|---|

|
Artículo redactado por Avengium Para proponer cualquier cambio o adición, consulte a los redactores. |
|---|